
Templar SN3 Bittensor explained: Covenant-72B, the SparseLoCo breakthrough, the SN3 alpha token, and an honest read on decentralized AI training in 2026.
Author: Kritika Gupta
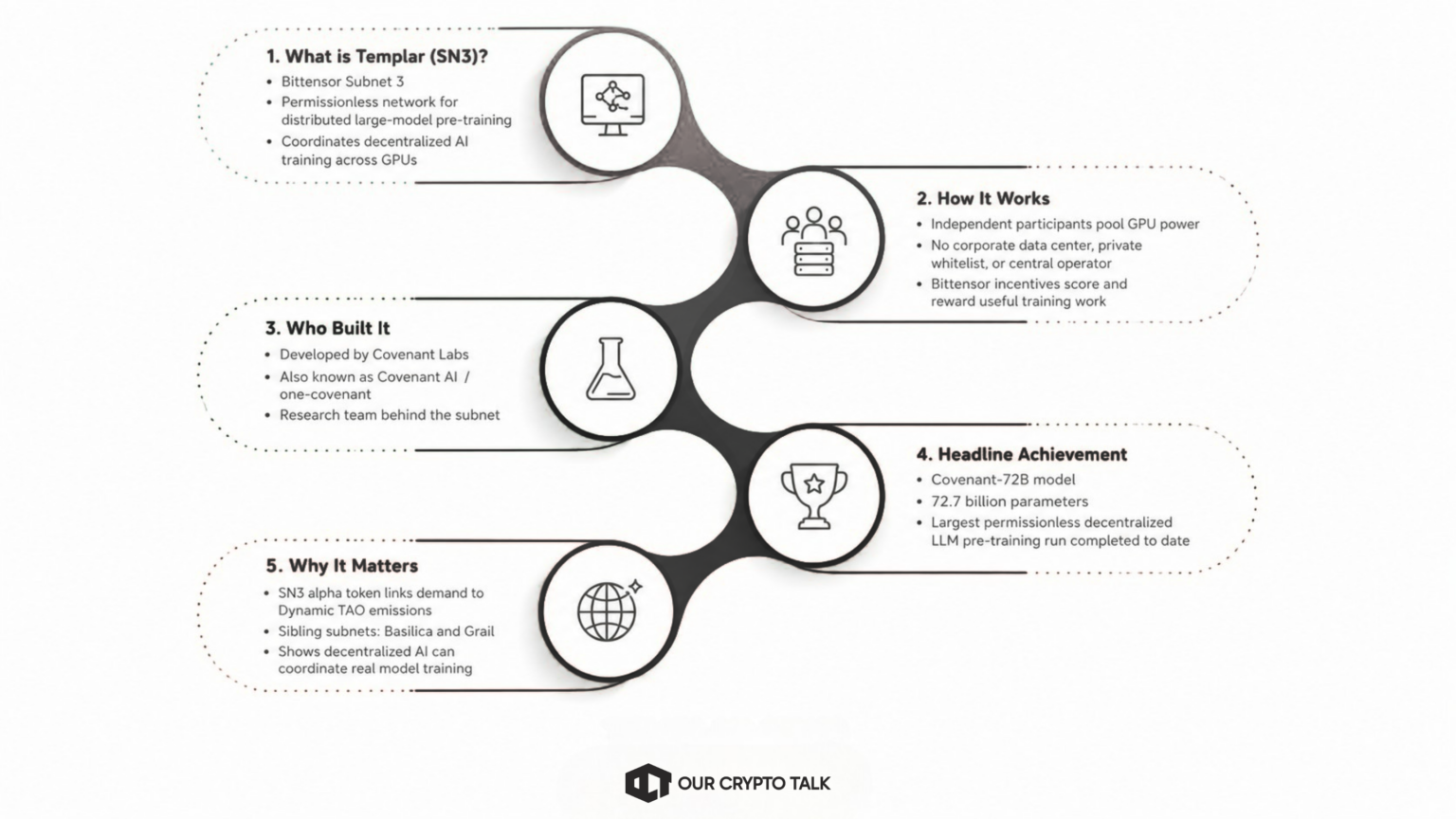
Templar Bittensor became impossible to ignore after Covenant Labs trained Covenant-72B, a 72.7-billion-parameter model through a permissionless decentralized network.
Templar is Bittensor’s Subnet 3, or SN3, and it focuses on distributed large-model pre-training. In plain terms, Templar Bittensor lets independent participants pool GPUs and help train large language models without relying on a corporate data center, a private whitelist, or one centralized operator.
The subnet uses Bittensor’s incentive layer to coordinate compute, score useful training work, and reward contributors. That makes Templar one of the clearest examples of Bittensor moving beyond AI-token narratives and toward real decentralized model training.
Key facts at a glance:
That makes Templar Bittensor important for one clear reason: it shows that decentralized AI networks can coordinate real model training, not just inference or token incentives. For Bittensor, SN3 became one of the strongest proof points for the subnet model.
Further reading: Bittensor (TAO) Guide
On March 10, 2026, Templar completed Covenant-72B, a 72-billion-parameter large language model trained through Bittensor Subnet 3. This milestone matters because the network trained the model across more than 70 independent, permissionless nodes instead of one centralized AI data center.
The run used roughly 1.1 trillion training tokens and commodity GPUs connected over ordinary residential and commercial internet. Participants did not rely on a private interconnect, a corporate cluster, or a whitelist. Instead, Templar coordinated the training process through Bittensor’s subnet incentives and validation systems.
That makes Covenant-72B one of the clearest technical proof points for decentralized AI training. Many decentralized AI projects focus on inference, compute marketplaces, or model access. However, Templar targeted the harder problem: large-model pre-training across an open network.
According to Templar’s published, self-reported results, Covenant-72B scored about 67.1 on MMLU. That placed it in the same broad performance range as Meta’s LLaMA-2-70B, which Templar reported at 65.6 under comparable evaluation. The team also reported competitive results across other reasoning and knowledge benchmarks, including ARC-Challenge, ARC-Easy, and PIQA.
Readers should treat those numbers properly. They come from Templar’s official technical materials and model release, not from a fully independent market-wide audit. Therefore, writers, researchers, and investors should verify the benchmark table against the official Covenant-72B paper, model card, and released weights before citing the figures as settled performance data.
Templar also released the model weights and checkpoints publicly under the Apache license. That open release gave researchers a direct way to inspect, test, fine-tune, and benchmark the model.
The milestone does not prove that decentralized training has caught the 2026 AI frontier. However, it does prove something important for crypto readers: a permissionless Bittensor subnet trained and released a usable 72B-class model without centralized infrastructure.
Templar Bittensor did not begin as the loudest AI subnet on Bittensor. For much of its early life, Subnet 3 operated as low-profile distributed-training infrastructure. It existed as one subnet among many, focused on coordinating compute and moving training data across a permissionless network rather than shipping a headline model.
That changed with Covenant-72B. The project moved from infrastructure work to model architecture and execution. Instead of only proving that independent nodes could process data and exchange updates, Templar showed that a decentralized subnet could help train a large language model from the ground up.
This shift created the turning point in Templar’s story. Distributed AI infrastructure often sounds useful, but markets usually need a concrete artifact before they care. Covenant-72B gave them one. It turned SN3 from a technical backend into a visible proof point for Bittensor’s decentralized training thesis.
The arc matters because decentralized AI faces a credibility gap. Many projects claim they can coordinate compute, reward useful work, or challenge centralized labs. However, Templar delivered a model that researchers could inspect and test. As a result, the subnet helped put decentralized training on the map as an engineering path, not just a crypto narrative.
Still, writers should handle SN3’s early history carefully. Secondary accounts of the subnet’s lineage, early contributors, and any operator transitions vary. Therefore, any detailed timeline should be verified against primary sources, including Bittensor on-chain records, subnet registration history, emission data, validator and miner activity, official Covenant Labs materials, and reliable Bittensor explorers.
The clean takeaway is this: Templar started as quiet training infrastructure, then became a model-building subnet. Covenant-72B made that transition visible.
Decentralized AI sounds easier when people talk about inference. Inference means running a finished model. Teams can split that work across GPUs, route requests to different nodes, batch user prompts, or run smaller quantized models on consumer hardware. The model already exists, so the system mainly needs to serve outputs reliably.

Training creates a much harder problem. During training, the model keeps changing. Every step requires nodes to compute gradients, share updates, compare results, and move toward one coherent set of weights. If the network fails to coordinate those updates properly, the model does not converge.
Centralized AI labs solve this problem with tightly coupled infrastructure. They use hyperscale data centers, high-bandwidth interconnects, and specialized networking systems that move information quickly between GPUs. This setup lets thousands of chips behave like one coordinated training machine.
A permissionless network does not get those advantages. Nodes may run different hardware. Some participants may join late, leave mid-run, or submit weaker updates. Internet connections may vary by region, speed, and reliability. Meanwhile, the training process still needs to keep moving toward a single useful model.
That is why decentralized training sits at the hardest end of the AI infrastructure stack. It must handle constant gradient updates, unstable participation, bandwidth limits, latency, verification, and incentive alignment at the same time.
Before Covenant-72B, many researchers and market participants assumed large-model pre-training would remain centralized. The coordination cost looked too high. The hardware gap looked too wide. The networking demands looked too strict.
Templar Bittensor made the achievement notable because it challenged that assumption directly. A permissionless subnet trained a 72B-class model across independent nodes without a private data center or high-speed corporate interconnect. That does not mean decentralized training has solved every frontier AI problem. However, it does show that open networks can coordinate far more complex AI work than simple inference.
Further reading: Yuma Consensus explainer
Distributed training runs into one bottleneck before almost anything else: communication. Every node must keep sharing training updates with the rest of the network. In a data center, high-speed interconnects handle that flow. Over ordinary home or business internet, bandwidth quickly becomes the limiting factor.
Templar Bittensor addressed that bottleneck with SparseLoCo, the compression approach behind the Covenant-72B run. In plain English, SparseLoCo made the updates small enough for independent nodes to train together without needing expensive data-center networking.
It did this through three main techniques.
First, SparseLoCo used sparsification. Instead of sending every gradient update, nodes shared only the most important pieces. This reduced the amount of information that needed to move across the network during each training round.
Second, it used aggressive 2-bit quantization. That means the system compressed each value down to roughly two bits. This step cut the size of each update dramatically, which made transmission over normal internet connections more realistic.
Third, it used error feedback. When the system dropped or compressed information, it did not simply forget that signal. Instead, it carried the missing information forward and folded it into later updates. This helped preserve training quality while still reducing communication load.
Together, these techniques reduced communication overhead by roughly 146 times compared with naive dense gradient exchange, according to the team’s published materials.
That number matters because it explains why Covenant-72B could happen outside a centralized AI cluster. Participants could contribute useful training work without relying on private interconnects, hyperscale infrastructure, or tightly controlled hardware environments.
The deeper technical details belong in the SparseLoCo paper and the Covenant-72B technical report. However, the high-level takeaway is simple: Templar made decentralized training practical by shrinking the communication problem.
Further reading: dTAO explainer
Covenant Labs did not build Templar as a one-off model experiment. It positioned SN3 as part of a wider decentralized AI stack on Bittensor.
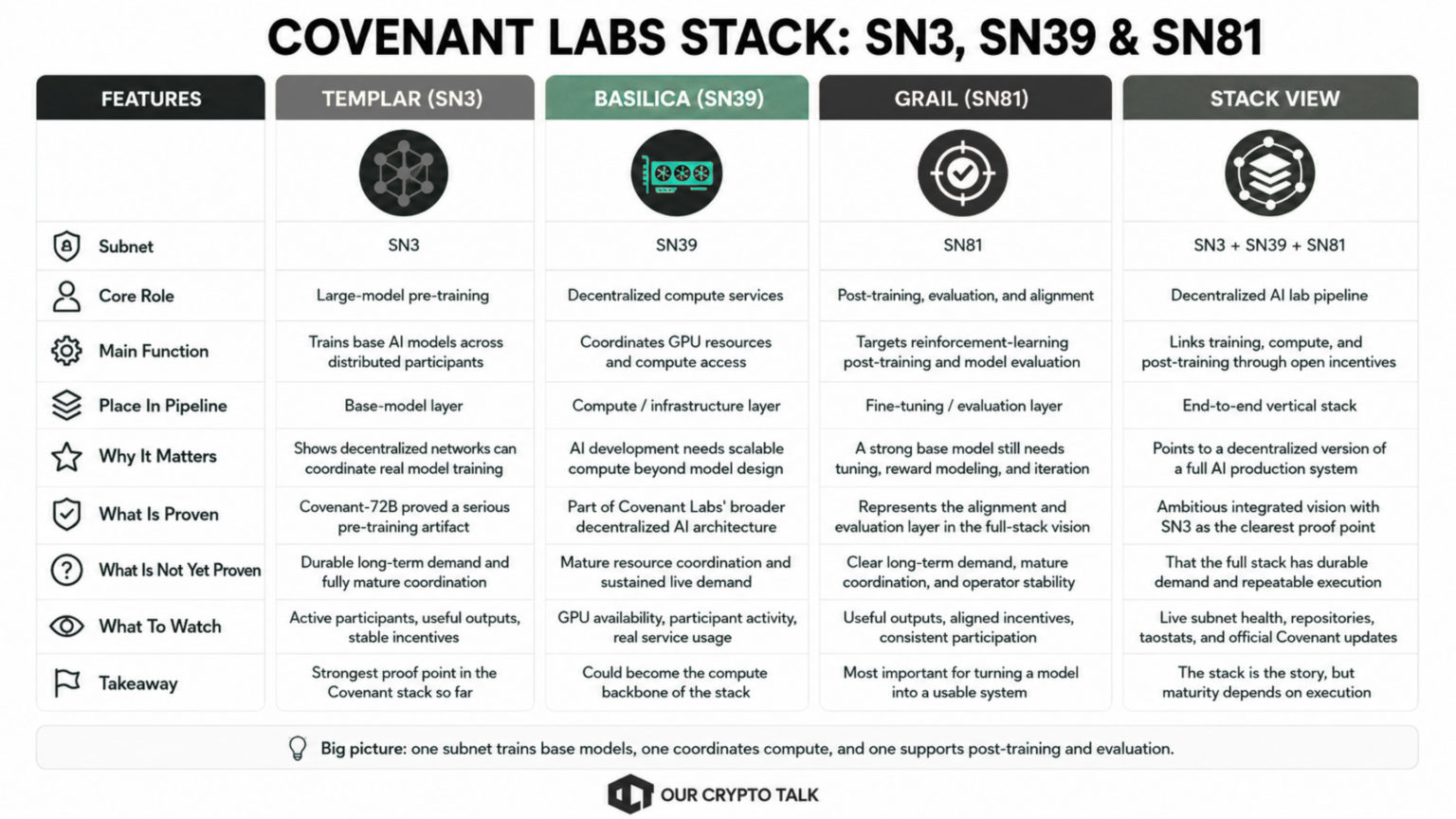
The stack includes three connected subnets. Templar, SN3, handles large-model pre-training. Basilica, SN39, focuses on decentralized compute services and GPU resource coordination. Grail, SN81, targets reinforcement-learning post-training, model evaluation, and alignment work.
Together, these subnets sketch something more ambitious than a single model release. They point toward a decentralized version of a full AI lab pipeline. In that structure, one subnet helps train base models, another coordinates compute resources, and another supports post-training and evaluation. Instead of one company owning the full stack, Bittensor subnets would coordinate each layer through open incentives.
That vertical integration matters because AI model development does not stop at pre-training. A strong base model still needs compute access, fine-tuning, evaluation, reward modeling, and continuous iteration. If Covenant Labs can connect these layers effectively, the stack could become a more complete decentralized AI production system.
However, readers should size the strategy honestly. Covenant-72B proved that the pre-training layer could produce a serious technical artifact. It did not prove that the full stack has durable demand, mature coordination, or long-term operator stability. The integrated vision remains more ambitious than fully proven.
That distinction matters for crypto readers. Markets often price subnets around future narratives, but infrastructure needs repeated execution. SN3, SN39, and SN81 must show active participants, useful outputs, clear incentives, and real demand beyond launch-cycle attention.
Before publication, writers should verify the current status of each subnet through official Covenant Labs channels, Bittensor explorers, taostats.io, and recent repository activity. The stack is the story, but its maturity depends on live subnet health, not only past announcements.
Covenant-72B attracted attention beyond the usual Bittensor and crypto circles. That mattered because decentralized AI often struggles to move from token narrative to technical credibility.

NVIDIA chief executive Jensen Huang compared Bittensor’s approach to a “Folding@home for AI.” The comparison pointed to a familiar idea: distributed contributors can coordinate compute for large scientific or technical workloads. In this case, the workload was large-scale AI training rather than protein folding or volunteer research compute.
Anthropic co-founder Jack Clark also highlighted the run in a write-up on AI research progress. He framed the development around the political economy of AI and treated it as a project worth watching. That attention helped place Covenant-72B inside a broader debate about who gets to build powerful AI systems: centralized labs, open-source communities, or permissionless compute networks.
Crypto commentators then called the release “Bittensor’s DeepSeek moment.” The phrase linked Templar to the wider market reaction around efficient, open AI models that challenged assumptions about closed-lab dominance. For Bittensor, the label gave the subnet story a clear narrative hook.
The institutional backdrop also helped. Grayscale’s TAO ETF filing kept Bittensor in front of more traditional crypto investors, while rising subnet valuations showed growing demand for AI-linked on-chain exposure. Together, these factors amplified attention around SN3 and its alpha token.
However, readers should treat this as third-party attention, not token endorsement. Huang and Clark recognized the technical direction and broader implications. They did not validate the SN3 alpha token as an investment. The real takeaway is narrower and stronger: serious AI observers noticed Covenant-72B because it made permissionless training look more credible.
Further reading: Bittensor vs Render and Bittensor (TAO) Guide
Covenant-72B deserves credit because it proves something real. Templar showed that a permissionless network can coordinate large-model pre-training across independent participants, commodity hardware, and ordinary internet connections. That alone makes it a serious technical milestone for decentralized AI.
What it proves: decentralized training can produce a real model, not just a token narrative. The run ended with publicly released weights, checkpoints, and benchmark results that researchers could inspect. It also showed that Bittensor’s subnet model can coordinate useful AI work across open contributors when the incentives, validation, and communication design line up.
That is a genuine first at this scale. Before Covenant-72B, many people treated frontier-scale pre-training as a task that only hyperscale AI labs could handle. Templar challenged that assumption. It showed that an open network could train a 72B-class model and produce a usable artifact at the end.
However, the achievement needs accurate sizing.
What it does not prove: Covenant-72B does not prove that decentralized training has caught the current AI frontier. The model looks competitive with Meta’s LLaMA-2-70B, a 2023-era benchmark, not with the strongest frontier systems of 2026. Leading AI labs now train with larger budgets, stronger data pipelines, longer context windows, more advanced post-training, and faster iteration cycles.
That distinction matters. Covenant-72B validates the method and its scaling path at a meaningful level. It does not establish parity with OpenAI, Anthropic, Google DeepMind, Meta’s newest systems, or other leading labs.
Still, that limitation should not dilute the milestone. A fair read can hold both ideas at once. Templar did not beat the frontier, but it did move decentralized training from theory into evidence. It gave the market and research community a working example of permissionless model pre-training at serious scale.
For crypto readers, that is the useful takeaway. Covenant-72B proved that decentralized AI can create real technical output. Now the thesis depends on repeatability, stronger models, continued operators, and sustained developer usage.
Further reading: Bittensor Crypto Review
Covenant-72B did not only move the technical conversation. It also triggered a sharp market reaction around Templar’s SN3 alpha token and the broader TAO ecosystem.
Contemporaneous reports cited an SN3 alpha token rally of roughly 194% in one week after the Covenant-72B milestone. TAO also moved higher as the story spread across AI and crypto circles. At peak attention, the subnet’s valuation climbed into the hundreds of millions, helped by rising demand for Bittensor’s AI-linked subnet exposure.
The mechanism behind that move comes from dTAO and Taoflow. Under Bittensor’s Dynamic TAO model, each subnet has its own alpha token. When users stake TAO into a subnet, they create demand for that subnet’s alpha. In simple terms, stronger attention, stronger perceived value, or stronger expected emissions can pull more TAO into a subnet. That flow can push the alpha token higher and increase the subnet’s economic weight inside Bittensor.
This creates a direct market feedback loop. A major technical milestone can attract attention. Attention can bring TAO inflows. Those inflows can lift the subnet alpha price. Then the price action can attract even more speculative demand.
However, this is also where readers need caution. Subnet alpha tokens are thin, volatile, and often narrative-driven. Liquidity can shift quickly, and slippage can matter on both entry and exit. A real research achievement does not automatically create durable token value, recurring revenue, or long-term demand for the alpha token.
That distinction matters most for SN3. Covenant-72B gave Templar a genuine technical catalyst, but the token move still reflected market flows and speculation. Writers should verify all price, valuation, and performance figures live before publication.
Nothing in this section is financial advice.
Covenant-72B made decentralized training credible. The next question is whether Templar can become durable infrastructure, or whether it remains a landmark one-off model run.
The first signal to watch is follow-up models. Templar Bittensor needs to show whether its method can scale beyond Covenant-72B and move past the 2023-frontier performance bar. A stronger next model would matter more than another announcement cycle.
The second signal is the maturity of the wider Covenant Labs stack. SN3 handles pre-training, SN39 focuses on compute services, and SN81 targets post-training and evaluation. Together, they outline a decentralized AI lab pipeline. However, the stack still needs proof of active usage, reliable coordination, and sustained operator execution.
The third signal is real demand for the models Templar produces. Downloads, fine-tunes, integrations, benchmark replication, and developer adoption will say more than token flows. If researchers and builders use the models, the subnet gains credibility beyond market speculation.
The fourth signal is competition. Other distributed-training efforts may emerge inside Bittensor or outside it. Centralized labs may also adopt more open training methods, which could narrow Templar’s narrative advantage.
The honest takeaway is simple: Covenant-72B proved that permissionless large-model pre-training can work. Now Templar must prove that it can repeat, improve, and stay competitive as the AI frontier keeps moving.

10 Crypto Skills Quietly Printing Money While Everyone Else Gets Liquidated
Are Exchange Tokens a Good Investment in 2026? CEX vs DEX
Zcash vs Monero vs Dash: Best Privacy Coin in 2026?
Helium Worked in America. Can Dabba Win India?
10 Crypto Skills Quietly Printing Money While Everyone Else Gets Liquidated
Are Exchange Tokens a Good Investment in 2026? CEX vs DEX
Zcash vs Monero vs Dash: Best Privacy Coin in 2026?
Helium Worked in America. Can Dabba Win India?



