
Yuma Consensus turns validator scores into TAO rewards, powering Bittensor’s miner incentives and subnet reward logic.
Author: Kritika Gupta
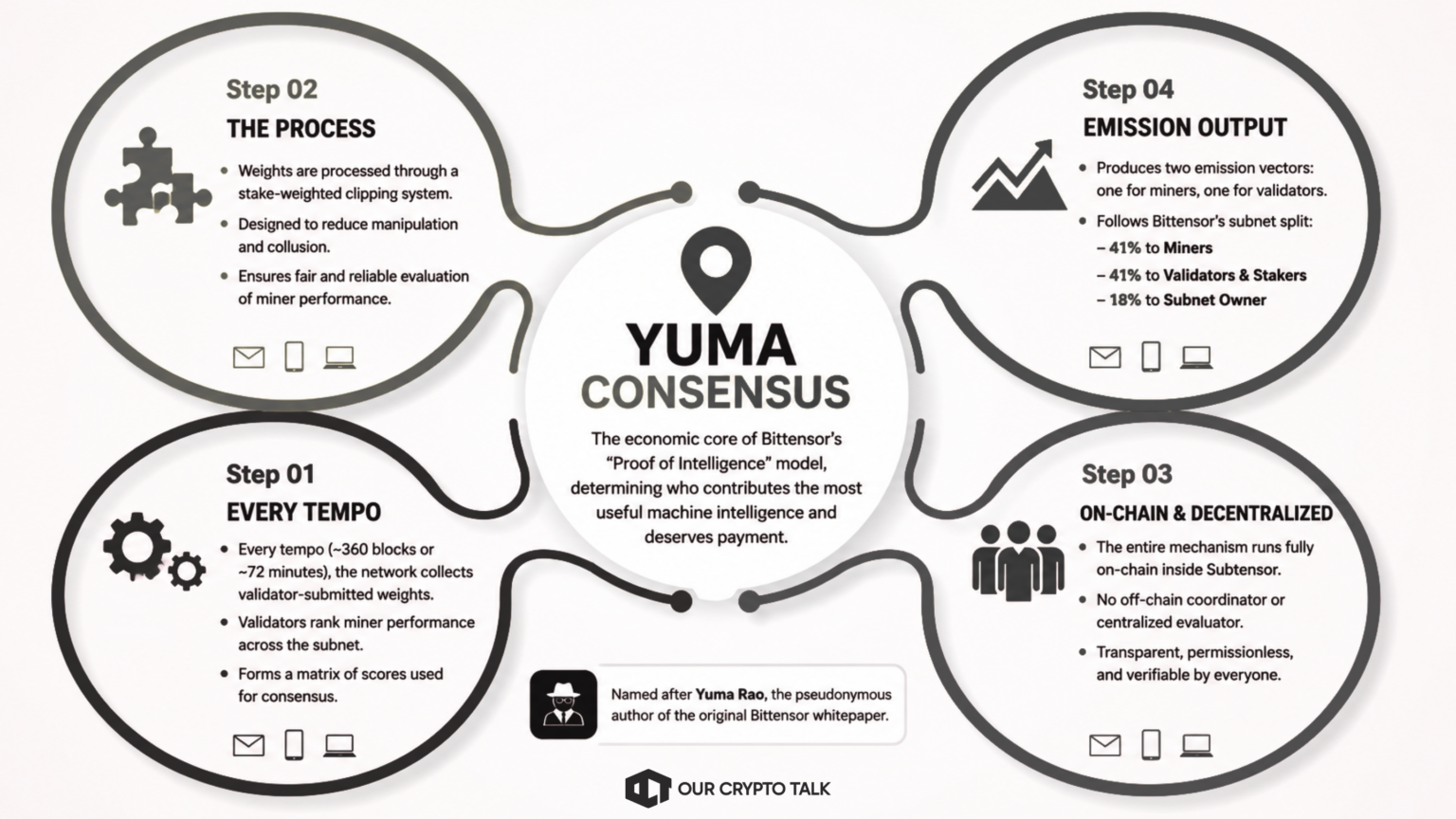
Every tempo, roughly 360 blocks or about 72 minutes, the network collects a matrix of validator-submitted weights that rank miner performance across a subnet. Yuma Consensus then processes those scores through a stake-weighted clipping system designed to reduce manipulation and collusion.
The algorithm ultimately produces two emission vectors: one for miner incentives and another for validator dividends. These emissions follow Bittensor’s standard subnet split, where 41% flows to miners, 41% flows to validators and their stakers, and 18% flows to the subnet owner. Importantly, the entire mechanism runs fully on-chain inside Subtensor rather than through an off-chain coordinator or centralized evaluator.
The system takes its name from Yuma Rao, the pseudonymous author of the original Bittensor whitepaper. In practice, Yuma Consensus forms the economic core of Bittensor’s “Proof of Intelligence” model because it determines who contributed the most useful machine intelligence and who deserves payment for it.
Bitcoin’s Proof of Work and most blockchains’ Proof of Stake solve one relatively clean problem: which version of history is true? They establish consensus over an objective ledger. Either a transaction happened or it did not. Either a block is valid or invalid.
Bittensor faces a far messier challenge.
The network does not need to decide whether a payment occurred. Instead, it needs to answer questions like: Was this AI response actually useful? Which model produced the best output? Which miner deserves rewards for contributing intelligence to the network?
There is no universally correct answer to those questions. A generated image, an inference response, or a training output does not come with a mathematically provable truth value. Instead, the system relies on many validators making subjective evaluations based on their own testing and ranking criteria.
That changes everything.
Bittensor therefore needs consensus over opinions rather than consensus over transactions. More importantly, it must reward honest evaluators without allowing large validators, colluding groups, or lazy actors to manipulate emissions for their own gain.
A simple average would fail because one large validator could inflate mediocre miners and redirect rewards. A pure majority vote would also fail because stake concentration could dominate outcomes. Meanwhile, completely open voting would invite spam, collusion, and coordinated farming.
Yuma Consensus exists specifically to solve this problem. It transforms noisy and self-interested evaluations into a stake-weighted economic system that rewards accurate judgment while limiting manipulation. In practice, the algorithm acts less like a traditional blockchain consensus engine and more like a decentralized market for machine intelligence.
That is what makes Bittensor fundamentally different from most crypto networks. The chain is not only securing history. It is trying to price intelligence itself.
Read more about Bittensor Subnets.
Four core components power Yuma Consensus: miners, validators, weights, and stake. Understanding these terms makes the rest of the system much easier to follow.
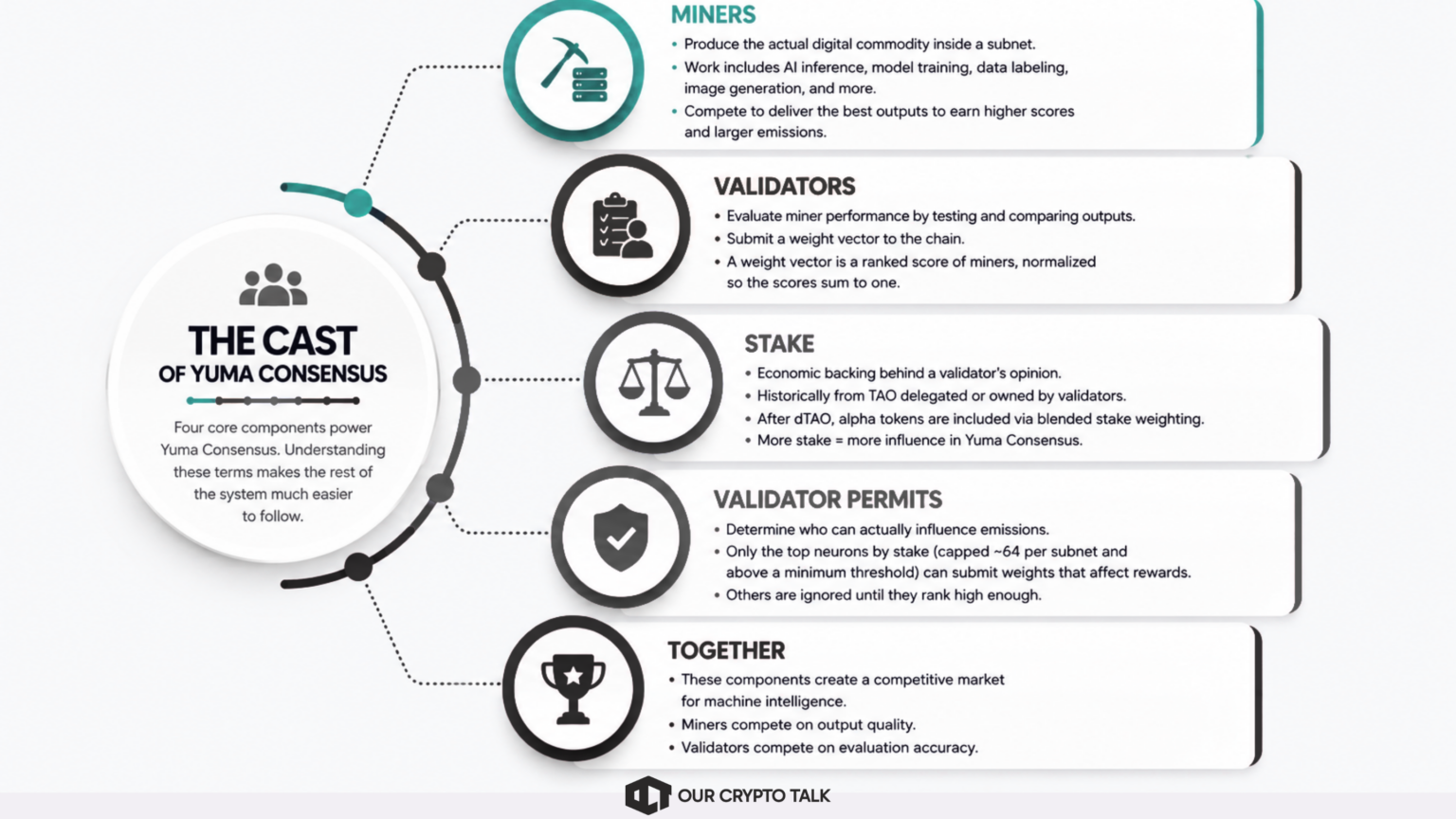
Miners produce the actual digital commodity inside a subnet. Depending on the subnet, that work can include AI inference, model training, data labeling, image generation, or other machine intelligence tasks. Miners continuously compete to deliver the best outputs because better performance attracts higher validator scores and larger emissions.
Validators evaluate miner performance. They query miners, test output quality, compare responses, and then submit a weight vector to the chain. A weight vector is simply a ranked score of the miners a validator tested, normalized so the scores sum to one.
Stake represents the economic backing behind a validator’s opinion. Historically, this stake came primarily from TAO delegated to or owned by validators. After dTAO, alpha tokens also became part of the equation through blended stake weighting. The more stake a validator controls, the more influence its evaluations carry inside Yuma Consensus. For the broader token mechanics, see the dTAO explainer.
Finally, validator permits determine who can actually influence emissions. Not every validator gets voting power. Instead, only the top neurons by stake, historically capped at roughly 64 active validators per subnet and above a minimum threshold, can submit weights that affect rewards. Others may still run validator nodes, but the chain ignores their scores until they climb high enough in the rankings.
Together, these components create a competitive market where miners compete on output quality and validators compete on evaluation accuracy.
If Yuma Consensus acts as the heart of a subnet, then the epoch acts as its heartbeat.
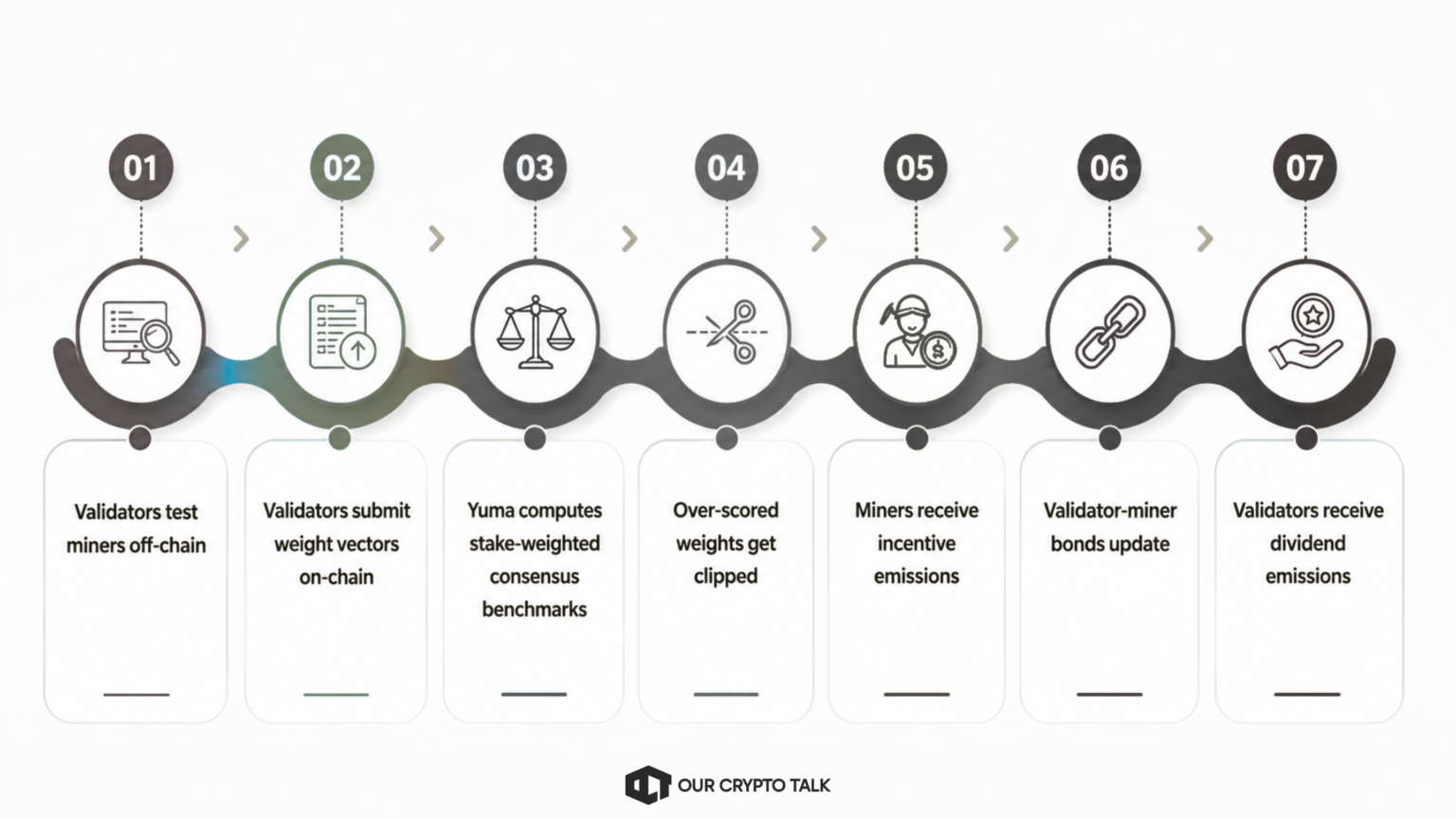
Validators evaluate miners continuously and mostly off-chain. They send prompts, test outputs, compare responses, and update their internal rankings in real time. However, the network does not distribute rewards continuously. Instead, settlement happens through a regular on-chain pulse known as the epoch.
Once per tempo, roughly every 360 blocks or about 72 minutes, Subtensor collects all validator weight submissions from the previous period and runs them through the full Yuma Consensus algorithm. This process converts subjective evaluations into actual emissions for miners, validators, and subnet owners.
That rhythm matters. Continuous settlement would create constant noise and open the door to extreme short-term gaming. Instead, the epoch gives the subnet a predictable cadence. Miners know rewards update at regular intervals, while validators know the network will evaluate their latest scores during the next pulse.
The heartbeat analogy works because scoring and settlement happen in different layers of the system. Off-chain evaluation behaves like continuous blood flow, while the epoch acts like a heartbeat that periodically pushes value through the network. Every major mechanism that follows, including clipping, bonds, incentives, and dividends, activates during this cycle.
This recurring pulse is what transforms ongoing AI work into synchronized on-chain economic rewards.
Yuma Consensus turns validator opinions into emissions through a structured pipeline. The easiest way to understand it is to think of a peer-review system for AI work. Miners submit the “papers,” validators act as reviewers, and the chain decides which scores deserve economic weight.
The peer-review analogy explains why this matters. In a normal review panel, several reviewers may grade the same paper. If one reviewer gives an extremely generous score that the rest of the panel does not support, the system should not let that outlier decide the paper’s reward. Yuma Consensus applies a similar idea to decentralized AI.
However, Bittensor adds an economic layer. Reviewers are not equal by default. Their influence depends on stake, and their long-term rewards depend on whether their judgment proves useful. A validator that consistently identifies strong miners early can build better bonds and earn more dividends. On the other hand, a validator that blindly boosts weak miners, copies others, or submits inflated weights loses influence in the reward process.
This makes Yuma Consensus more than a scoring engine. It is a reward market for machine intelligence. The algorithm tries to pay miners for useful work while paying validators for accurate judgment.
The protective core of Yuma Consensus revolves around two concepts: kappa and clipping.
Kappa is the consensus threshold parameter. In most subnet configurations, kappa is set to 0.5, meaning the algorithm looks for the score level that at least 50% of total validator stake agrees a miner deserves. Instead of trusting the loudest validator, Yuma Consensus trusts the weighted middle of the market.
Here is the intuition in plain language.
Imagine all validators scoring the same miner. The algorithm lines those validators up according to stake and searches for the highest score where a majority of economic stake still agrees the miner is at least that good. That score becomes the consensus benchmark.
Any validator that scores the miner significantly above this benchmark gets clipped. The network removes the inflated portion from both miner incentives and validator dividends. As a result, neither the validator nor the miner earns rewards from exaggerated scoring.
A simple example makes this easier to see.

Suppose three validators control 40%, 35%, and 25% of subnet stake. They score the same miner 0.9, 0.6, and 0.4 respectively. Since more than 50% of total stake supports a score of at least 0.6, the benchmark becomes 0.6. The validator who submitted 0.9 gets clipped down to 0.6.
That extra 0.3 effectively disappears.
This mechanism matters because it prevents a single validator or small colluding group from artificially boosting a preferred miner. Even if one large validator aggressively inflates scores, the system only rewards the portion supported by the broader stake-weighted majority.
In practice, clipping turns Yuma Consensus into a defense system against manipulation. It forces validators to stay close to collective economic reality rather than trying to game emissions.
Validators do not earn rewards simply for submitting scores. Yuma Consensus pays them through a system of bonds and dividends, which together reward validators that consistently identify strong miners before the broader market fully recognizes them.
A bond represents the relationship between a validator and a miner. Every epoch, the network updates that relationship using an exponential moving average, where recent observations carry the heaviest weight, typically around 0.9. In practice, this means validators strengthen their bonds by repeatedly supporting miners that later achieve strong consensus scores.
The design creates an important dynamic.
A validator cannot maximize rewards by randomly boosting miners or constantly changing opinions. Instead, the validator must consistently identify useful miners early and continue backing them as the rest of the subnet recognizes their quality. Over time, strong and accurate evaluations compound into stronger bonds.
Dividends then flow to validators based on two factors. First, validators earn from the strength of their bonds with highly-rated miners. Validators that formed strong relationships with top-performing miners receive a larger share of validator emissions.
Second, validators earn based on how closely their submitted weights align with the subnet’s stake-weighted consensus. If a validator constantly over-scores weak miners or submits noisy rankings, the clipping system weakens the economic value of those weights. This structure changes validator incentives completely.
The system does not reward the loudest participant, the validator with the most dramatic scores, or the actor trying to manipulate emissions. Instead, it rewards validators that repeatedly demonstrate accurate judgment over time.
The peer-review analogy fits again here. Imagine a reviewer who consistently recognizes strong research papers before the rest of the panel catches up. Over time, that reviewer develops credibility because their evaluations repeatedly prove correct. Another reviewer who constantly inflates mediocre papers loses influence because their judgment fails to match broader consensus.
Yuma Consensus applies the same logic to decentralized AI markets. Validators win by being early, consistent, and right.
For a broader look at Bittensor’s economic design and long-term thesis, see the Bittensor crypto review.
Yuma Consensus rewards validators whose scores align closely with subnet consensus. That creates a serious problem.
A lazy validator can avoid doing real evaluation work entirely.
Instead of testing miners independently, the validator can simply wait for honest validators to publish their weights, estimate the likely stake-weighted median, copy those scores, and collect dividends anyway. In effect, the copier free-rides on the work of validators actually spending compute, time, and bandwidth evaluating miner quality.
If this behavior spreads widely enough, the network breaks down. Why spend resources testing miners if copying produces similar rewards at lower cost? Over time, honest validators would earn less relative to copycats, real evaluation quality would decline, and subnet emissions would increasingly reward imitation rather than intelligence discovery.
Bittensor openly acknowledges this problem. More importantly, the OpenTensor Foundation has already shipped multiple defenses to make copying harder and less profitable.
The first major mitigation is Commit-Reveal.
Under this system, validators first commit encrypted versions of their weights on-chain rather than revealing them immediately. Only after the commitment window closes do validators reveal the actual values. This delay prevents copycats from reading honest validators’ weights in time to mirror them before the epoch settles.
The second mitigation is Liquid Alpha, also called Consensus-Based Weights, introduced around Bittensor 7.3. Liquid Alpha changes how validator dividends are calculated. Instead of rewarding validators purely for matching final consensus, the mechanism places more value on validators that independently identify strong miners early. As a result, validators that simply copy the emerging consensus later in the process earn weaker bond growth and lower dividend potential.
However, neither solution fully eliminates the problem.
Subnet owners still need to configure these systems correctly. Poor Commit-Reveal settings or weak Liquid Alpha parameters can reopen opportunities for copying behavior. Moreover, sophisticated validators continuously search for new ways to infer consensus before full revelation.
That is why the weight-copying problem remains an ongoing arms race rather than a solved issue. This matters because the credibility of Bittensor depends on whether honest evaluation remains economically worthwhile. If real validators cannot consistently out-earn passive copiers, the entire “Proof of Intelligence” model weakens.
For a broader critique of the network’s incentive structure, see the Bittensor Ponzi analysis 2026 article.
One of the biggest sources of confusion in the Bittensor ecosystem is the relationship between Yuma Consensus and dTAO. Many users assume dTAO replaced Yuma Consensus. It did not.
Yuma Consensus still runs inside every subnet exactly as before. Validators continue evaluating miners, submitting weight vectors, and passing those weights through clipping, bonds, and dividend calculations during every epoch. The algorithm still decides how a subnet’s emissions split among its miners, validators, and subnet owner.
What changed with dTAO was a different layer of the system.
Before dTAO, root validators played a major role in deciding how much TAO each subnet received from the network-wide emission pool. After dTAO, that allocation became market-driven. Instead of relying primarily on root-validator voting, subnet emissions now depend on alpha token demand, staking behavior, and subnet market value.
In simple terms, Yuma Consensus still answers the internal subnet question:
Which miners and validators inside this subnet deserve rewards? Meanwhile, dTAO answers the external network question: How much TAO should this subnet receive relative to other subnets? There is, however, one direct connection between the two systems: the tao_weight parameter.
Currently set around 0.18, tao_weight blends TAO stake and subnet alpha stake when calculating validator influence inside Yuma Consensus. This mechanism helped the network transition gradually into dTAO rather than abruptly replacing the older TAO-dominated weighting structure. Validators therefore gained increasing exposure to subnet-native alpha economics without instantly discarding the original TAO stake model.
One final clarification matters because the naming regularly confuses newer users: Yuma Consensus, the algorithm, is completely separate from Yuma, the DCG asset manager that later adopted the same name inspired by Yuma Rao.
Yuma Consensus is one of the most ambitious experiments in crypto because it attempts to put a market price on intelligence itself.
Most blockchains coordinate around objective events such as transactions, balances, or block production. Bittensor tries to coordinate around something far less concrete: the usefulness of machine-generated work. Yuma Consensus exists to convert subjective judgments about AI output into real economic rewards without relying on a centralized grader, company, or API gatekeeper.
That is the breakthrough idea.
In theory, the system creates an open market where miners compete to produce useful intelligence and validators compete to identify quality accurately. If the incentives hold, the network can continuously direct emissions toward the most valuable machine work through stake and market dynamics alone.
However, the criticisms are real and still unresolved. Stake concentration remains a major concern because a relatively small group of large validators can still shape consensus outcomes across many subnets. Even with clipping and stake-weighted medians, economic influence is not evenly distributed across the network.
At the same time, the weight-copying problem has not disappeared. Commit-Reveal and Liquid Alpha improved the system substantially, but validators continue searching for ways to infer consensus signals early and exploit reward mechanics. The result is a permanent cat-and-mouse game between honest evaluation and strategic gaming.
That tension matters because Yuma Consensus only works if real validators consistently earn more than passive imitators.
Even so, the system represents a genuine attempt to solve a problem most blockchains never tried to address: decentralized pricing of intelligence. Whether it ultimately succeeds or fails, Yuma Consensus has already pushed crypto deeper into AI-native economic design.
For a broader look at Bittensor’s price prediction market, read Bittensor ($TAO) Price Prediction




